Analytics API
The Moodle Analytics API allows Moodle site managers to define prediction models that combine indicators and a target.
The target is the event we want to predict. The indicators are what we think will lead to an accurate prediction of the target.
Moodle is able to evaluate these models and, if the prediction accuracy is high enough, Moodle internally trains a machine learning algorithm by using calculations based on the defined indicators within the site data. Once new data that matches the criteria defined by the model is available, Moodle starts predicting the probability that the target event will occur. Targets are free to define what actions will be performed for each prediction, from sending messages or feeding reports to building new adaptive learning activities.
An example of a model you may be interested in is the detection of students who are at risk of dropping out.
Possible indicators for this include:
- a lack of participation in previous activities
- poor grades in previous activities
The target would be whether the student is able to complete the course or not.
Moodle uses these indicators and the target for each student in a finished course to predict which students are at risk of dropping out in ongoing courses.
Summary
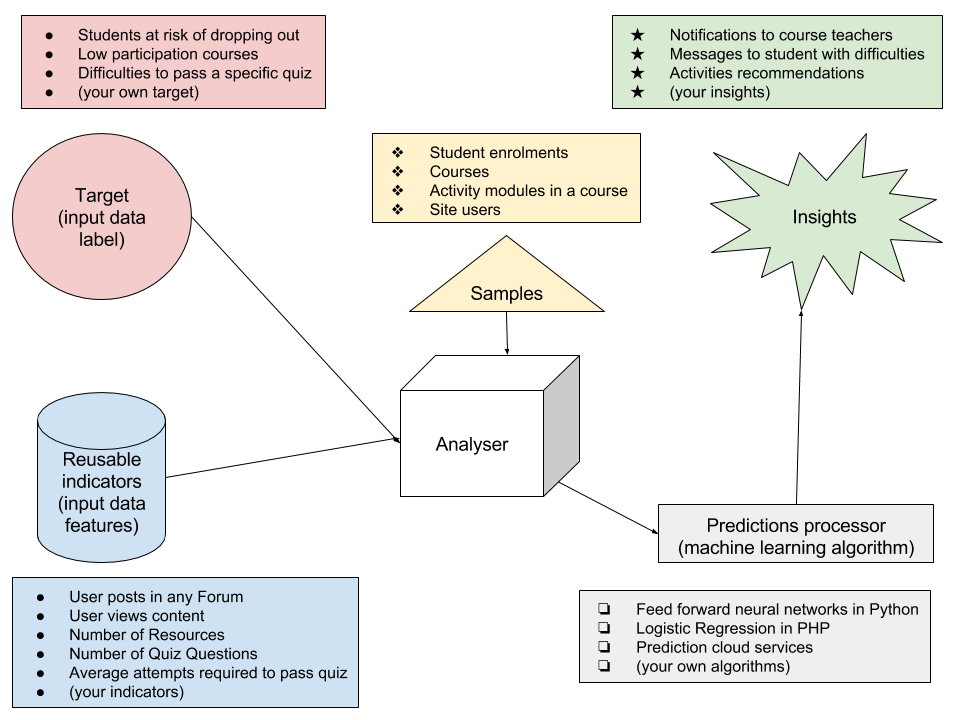
API components
This diagram shows the main components of the analytics API and the interactions between them.
Data flow
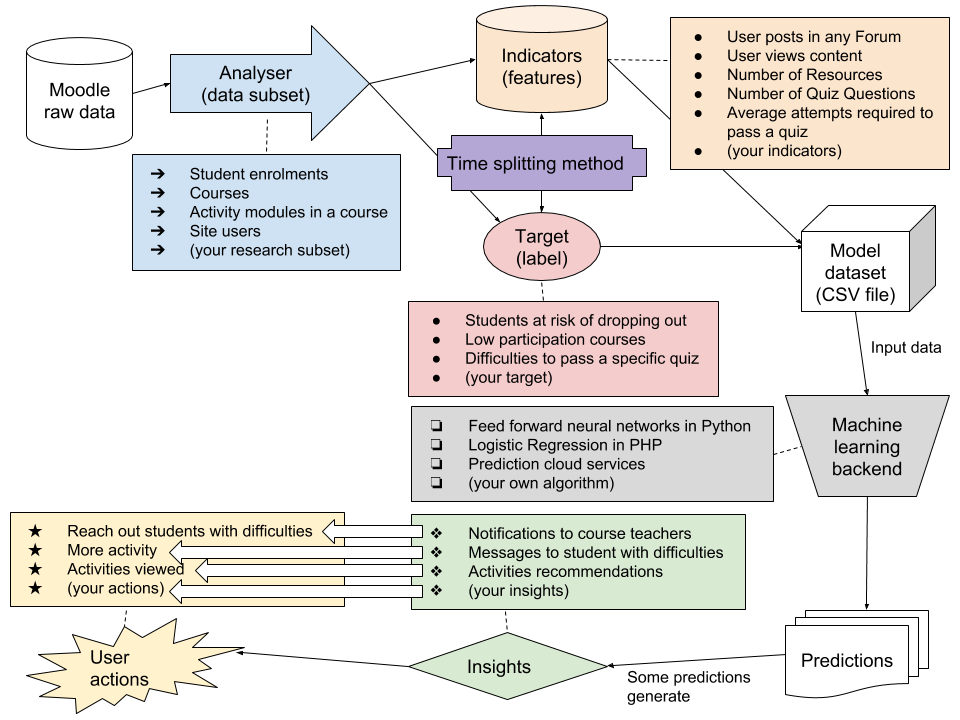
The diagram below shows the different stages data goes through, from the data a Moodle site contains to actionable insights.
API classes diagram
This is a summary of the API classes and their relationships. It groups the different parts of the framework that can be extended by 3rd parties to create your own prediction models.
-79d7ad9966f55e510015cc027a18608e.svg)
Built-in models
People use Moodle in very different ways and even courses on the same site can vary significantly. Moodle core only includes models that have been proven to be good at predicting in a wide range of sites and courses. Moodle provides two built-in models:
To diversify the samples and to cover a wider range of cases, the Moodle HQ research team is collecting anonymised Moodle site datasets from collaborating institutions and partners to train the machine learning algorithms with them. The models that Moodle is shipped with will be likely better at predicting on the sites of participating institutions, although some other datasets are used as test data for the machine learning algorithm to ensure that the models are good enough to predict accurately in any Moodle site.
Even if the models included in Moodle core are already trained by Moodle HQ, each different site will continue training that site machine learning algorithms with its own data, which will lead to better prediction accuracy over time.
Concepts
The following definitions are included for people not familiar with machine learning concepts:
Training
This is the process to be run on a Moodle site before being able to predict anything. This process records the relationships found in site data from the past so the analytics system can predict what is likely to happen under the same circumstances in the future. What we train are machine learning algorithms.
Samples
The machine learning backends we use to make predictions need to know what sort of patterns to look for, and where in the Moodle data to look. A sample is a set of calculations we make using a collection of Moodle site data. These samples are unrelated to testing data or phpunit data, and they are identified by an id matching the data element on which the calculations are based. The id of a sample can be any Moodle entity id: a course, a user, an enrolment, a quiz attempt, etc. and the calculations the sample contains depend on that element. Each type of Moodle entity used as a sample helps develop the predictions that involve that kind of entity. For example, samples based on Quiz attempts will help develop the potential insights that the analytics might offer that are related to the Quiz attempts by a particular group of students. See the Analyser documentation for more information on how to use analyser classes to define what is a sample.
Prediction model
As explained above, a prediction model is a combination of indicators and a target. System models can be viewed in Site administration > Analytics > Analytics models.
The relationship between indicators and targets is stored in analytics_models database table.
The class \core_analytics\model manages all of a model's related actions. evaluate(), train() and predict() forward the calculated indicators to the machine learning backends. \core_analytics\model delegates all heavy processing to analysers and machine learning backends. It also manages prediction models evaluation logs.
\core_analytics\model class is not expected to be extended.
Static models
Some prediction models do not need a powerful machine learning algorithm behind them processing large quantities of data to make accurate predictions. There are obvious events that different stakeholders may be interested in knowing that we can easily calculate. These Static model predictions are directly calculated based on indicator values. They are based on the assumptions defined in the target, but they should still be based on indicators so all these indicators can still be reused across different prediction models. For this reason, static models are not editable through Site administration > Analytics > Analytics models user interface.
Some examples of possible static models:
- Courses without teaching activity
- Courses with students submissions requiring attention and no teachers accessing the course
- Courses that started 1 month ago and never accessed by anyone
- Students that have never logged into the system
Moodle can already generate notifications for the examples above, but there are some benefits on doing it using the Moodle analytics API:
- Everything is easier and faster to code from a development point of view as the analytics subsystem provides APIs for everything
- New Indicators will be part of the core indicators pool that researchers (and 3rd party developers in general) can reuse in their own models
- Existing core indicators can be reused as well (the same indicators used for insights that depend on machine learning backends)
- Notifications are displayed using the core insights system, which is also responsible of sending the notifications and all related actions.
- The Analytics API tracks user actions after viewing the predictions, so we can know if insights result in actions, which insights are not useful, etc. User responses to insights could themselves be defined as an indicator.
Analyser
Analysers are responsible for creating the dataset files that will be sent to the machine learning processors. They are coded as PHP classes. Moodle core includes some analysers that you can use in your models.
The base class \core_analytics\local\analyser\base does most of the work. It contains a key abstract method, get_all_samples(). This method is what defines the sample unique identifier across the site. Analyser classes are also responsible of including all site data related to that sample id; this data will be used when indicators are calculated. e.g. A sample id user enrolment would include data about the course, the course context and the user. Samples are nothing by themselves, just a list of ids with related data. They are used in calculations once they are combined with the target and the indicator classes.
Other analyser class responsibilities:
- Define the context of the predictions
- Discard invalid data
- Filter out already trained samples
- Include the time factor (time range processors, explained below)
- Forward calculations to indicators and target classes
- Record all calculations in a file
- Record all analysed sample ids in the database
If you are introducing a new analyser, there is an important non-obvious fact you should know about: for scalability reasons, all calculations at course level are executed in per-course basis and the resulting datasets are merged together once all site courses analysis is complete. This is for performance reasons: depending on the sites' size it could take hours to complete the analysis of the entire site. This is a good way to break the process up into pieces. When coding a new analyser you need to decide if you want to extend \core_analytics\local\analyser\by_course (your analyser will process a list of courses), \core_analytics\local\analyser\site-wide (your analyser will receive just one analysable element, the site) or create your own analyser for activities, categories or any other Moodle entity.
Target
Targets are the key element that defines the model. As a PHP class, targets represent the event the model is attempting to predict (the dependent variable in supervised learning). They also define the actions to perform depending on the received predictions.
Targets depend on analysers, because analysers provide them with the samples they need. Analysers are separate entities from targets because analysers can be reused across different targets. Each target needs to specify which analyser it is using. Here are a few examples to clarify the difference between analysers, samples and targets:
- Target: 'students at risk of dropping out'. Analyser provides sample: 'course enrolments'
- Target: 'spammer'. Analyser provides sample: 'site users'
- Target: 'ineffective course'. Analyser provides sample: 'courses'
- Target: 'difficulties to pass a specific quiz'. Analyser provides sample: 'quiz attempts in a specific quiz'
A callback defined by the target will be executed once new predictions start coming so each target have control over the prediction results.
The API supports binary classification, multi-class classification and regression, but the machine learning backends included in core do not yet support multi-class classification or regression, so only binary classifications will be initially fully supported. See MDL-59044 and MDL-60523 for more information.
Although there is no technical restriction against using core targets in your own models, in most cases each model will implement a new target. One possible case in which targets might be reused would be to create a new model using the same target and a different sets of indicators, for A/B testing
Insights
Another aspect controlled by targets is insight generation. Insights represent predictions made about a specific element of the sample within the context of the analyser model. This context will be used to notify users with the moodle/analytics:listinsights capability (the teacher role by default) about new insights being available. These users will receive a notification with a link to the predictions page where all predictions of that context are listed.
A set of suggested actions will be available for each prediction. In cases like Students at risk of dropping out the actions can be things like sending a message to the student, viewing the student's course activity report, etc.
Indicator
Indicator PHP classes are responsible for calculating indicators (predictor value or independent variable in supervised learning) using the provided sample. Moodle core includes a set of indicators that can be used in your models without additional PHP coding (unless you want to extend their functionality).
Indicators are not limited to a single analyser like targets are. This makes indicators easier to reuse in different models. Indicators specify a minimum set of data they need to perform the calculation. The indicator developer should also make an effort to imagine how the indicator will work when different analysers are used. For example an indicator named Posts in any forum could be initially coded for a Shy students in a course target; this target would use course enrolments analyser, so the indicator developer knows that a course and an enrolment will be provided by that analyser, but this indicator can be easily coded so the indicator can be reused by other analysers like courses or users'. In this case the developer can chose to require course or user, and the name of the indicator would change according to that. For example, User posts in any forum could be used in a user-based model like Inactive users and in any other model where the analyser provides user data; Posts in any of the course forums could be used in a course-based model like Low participation courses.''
The calculated value can go from -1 (minimum) to 1 (maximum). This requirement prevents the creation of "raw number" indicators like absolute number of write actions, because we must limit the calculation to a range, e.g. -1 = 0 actions, -0.33 = some basic activity, 0.33 = activity, 1 = plenty of activity. Raw counts of an event like "posts to a forum" must be calculated in a proportion of an expected number of posts. There are several ways of doing this. One is to define a minimum desired number of events, e.g. 3 posts in a forum represents "some" activity, 6 posts represents adequate activity, and 10 or more posts represents the maximum expected activity. Another way is to compare the number of events per individual user to the mean or median value of events by all users in the same context, using statistical values. For example, a value of 0 would represent that the student posted the same number of posts as the mean of all student posts in that context; a value of -1 would indicate that the student is 2 or 3 standard deviations below the mean, and a +1 would indicate that the student is 2 or 3 standard deviations above the mean.
This kind of comparative calculation has implications to pedagogy: it suggests that there is a ranking of students from best to worst, rather than a defined standard all students can reach. Please be aware of this when considering how indicators are presented to users.
Analysis intervals
Analysis intervals define when the system will calculate predictions and the portion of activity logs that will be considered for those predictions. They are coded as PHP classes and Moodle core includes some analysis intervals you can use in your models.
Analysis intervals were previously known as Time-splitting methods.
In some cases the time factor is not important and we just want to classify a sample. This is relatively simple. Things get more complicated when we want to predict what will happen in future. For example, predictions about Students at risk of dropping out are not useful once the course is over or when it is too late for any intervention.
Calculations involving time ranges can be a challenging aspect of some prediction models. Indicators need to be designed with this in mind and we need to include time-dependent indicators within the calculated indicators so machine learning algorithms are smart enough to avoid mixing calculations belonging to the beginning of the course with calculations belonging to the end of the course.
There are many different ways to split up a course into time ranges: in weeks, quarters, 8 parts, ten parts (tenths), ranges with longer periods at the beginning and shorter periods at the end... And the ranges can be accumulative (each one inclusive from the beginning of the course) or only from the start of the time range.
Many of the analysis intervals included in Moodle assume that there is a fixed start and end date for each course, so the course can be divided into segments of equal length. This allows courses of different lengths to be included in the same prediction model, but makes these analysis intervals useless for courses without fixed start or end dates, e.g. self-paced courses. These courses might instead use fixed time lengths such as weeks to define the boundaries of prediction calculations.
Machine learning backends
Documentation available in Machine learning backends.
Design
The system is designed as a Moodle subsystem and API. It lives in analytics/. All analytics base classes are located here.
Machine learning backends is a new Moodle plugin type. They are stored in lib/mlbackend.
Uses of the analytics API are located in different Moodle components, being core (lib/classes/analytics) the component that hosts general purpose uses of the API.
Interfaces
This API aims to be as extendable as possible. Any moodle component, including third party plugins, is able to define indicators, targets, analysers and time splitting methods. Analytics API will be able to find them as long as they follow the namespace conventions described below.
An example of a possible extension would be a plugin with indicators that fetch student academic records from the Universities' student information system; the site admin could build a new model on top of the built-in 'students at risk of drop out detection' adding the SIS indicators to improve the model accuracy or for research purposes.
This section does not include Machine learning backend interfaces. See Machine learning backends for more information on these.
Analysable (core_analytics\analysable)
Analysables are those elements in Moodle that contain samples. In most of the cases an analysable will be a course, although it can also be the site or any other Moodle element, e.g. an activity. Moodle core includes two analysers \core_analytics\course and \core_analytics\site.
They list of methods that need to be implemented is quite simple and does not require much explanation.
Analysable elements should be lazily loaded, otherwise you may encounter PHP memory issues. The reason is that analysers load all analysable elements in the site to calculate which ones are going to be calculated next (skipping the ones processed recently and stuff like that).
See core_analytics\course as an example of how this can be achieved.
Methods to implement:
/**
* The analysable unique identifier in the site.
*
* @return int.
*/
public function get_id();
/**
* The analysable human readable name
*
* @return string
*/
public function get_name();
/**
* The analysable context.
*
* @return \context
*/
public function get_context();
get_start and get_end define the start and end times that indicators will use for their calculations.
/**
* The start of the analysable if there is one.
*
* @return int|false
*/
public function get_start();
/**
* The end of the analysable if there is one.
*
* @return int|false
*/
public function get_end();
Analyser (core_analytics\local\analyser\base)
The get_analysables() method has been deprecated in favour of a new get_analysables_iterator() for performance reasons. This method returns the whole list of analysable elements in the site. Each model will later be able to discard analysables that do not match their expectations. e.g. if your model is only interested in quizzes with a time close the analyser will return all quizzes, your model will exclude the ones without a time close. This approach is supposed to make analysers more reusable.
/**
* Returns the list of analysable elements available on the site.
*
* A relatively complex SQL query should be set so that we take into account which analysable elements
* have already been processed and the order in which they have been processed. Helper methods are available
* to ease to implementation of get_analysables_iterator: get_iterator_sql and order_sql.
*
* @param string|null $action 'prediction', 'training' or null if no specific action needed.
* @return \Iterator
*/
public function get_analysables_iterator(?string $action = null)
get_all_samples and get_samples should return data associated with the sample ids they provide. This is important for 2 reasons:
- The data they provide alongside the sample origin is used to filter out indicators that are not related to what this analyser analyses. ''e.g. courses analysers do provide courses and information about courses, but not information about users, a is user profile complete indicator will require the user object to be available. A model using a courses analyser will not be able to use the is user profile complete indicator.
- The data included here is cached in PHP static vars; on one hand this reduces the amount of db queries indicators need to perform. On the other hand, if not well balanced, it can lead to PHP memory issues.
/**
* This function returns this analysable list of samples.
*
* @param \core_analytics\analysable $analysable
* @return array array[0] = int[] (sampleids) and array[1] = array (samplesdata)
*/
abstract public function get_all_samples(\core_analytics\analysable $analysable);
/**
* This function returns the samples data from a list of sample ids.
*
* @param int[] $sampleids
* @return array array[0] = int[] (sampleids) and array[1] = array (samplesdata)
*/
abstract public function get_samples($sampleids);
get_sample_analysable method is executing during prediction:
/**
* Returns the analysable of a sample.
*
* @param int $sampleid
* @return \core_analytics\analysable
*/
abstract public function get_sample_analysable($sampleid);
The sample origin is the moodle database table that uses the sample id as primary key.
/**
* Returns the sample's origin in moodle database.
*
* @return string
*/
abstract public function get_samples_origin();
sample_access_context associates a context to a sampleid. This is important because this sample predictions will only be available for users with moodle/analytics:listinsights capability in that context.
/**
* Returns the context of a sample.
*
* @param int $sampleid
* @return \context
*/
abstract public function sample_access_context($sampleid);
sample_description is used to display samples in Insights report:
/**
* Describes a sample with a description summary and a \renderable (an image for example)
*
* @param int $sampleid
* @param int $contextid
* @param array $sampledata
* @return array array(string, \renderable)
*/
abstract public function sample_description($sampleid, $contextid, $sampledata);
processes_user_data and join_sample_user methods are used by the analytics implementation of the privacy API. You only need to overwrite them if your analyser deals with user data. They are used to export and delete user data that is stored in analytics database tables:
/**
* Whether the plugin needs user data clearing or not.
*
* @return bool
*/
public function processes_user_data();
/**
* SQL JOIN from a sample to users table.
*
* More info in [https://github.com/moodle/moodle/blob/master/analytics/classes/local/analyser/base.php core_analytics\local\analyser\base]::join_sample_user
*
* @param string $sampletablealias The alias of the table with a sampleid field that will join with this SQL string
* @return string
*/
public function join_sample_user($sampletablealias);
You can overwrite a new one_sample_per_analysable() method if the analysables your model is using only have one sample. The insights generated by models will then include the suggested actions in the notification.
/**
* Just one sample per analysable.
*
* @return bool
*/
public static function one_sample_per_analysable() {
return true;
}
Indicator (core_analytics\local\indicator\base)
Indicators should generally extend one of these 3 classes, depending on the values they can return: core_analytics\local\indicator\binary for yes/no indicators, core_analytics\local\indicator\linear for indicators that return linear values and core_analytics\local\indicator\discrete for categorised indicators. In case you want your activity module to implement a community of inquiry indicator you can extend core_analytics\local\indicator\community_of_inquiry_indicator look for examples in Moodle core.
You can use required_sample_data to specify what your indicator needs to be calculated; you may need a user object, a course, a grade item... The default implementation does not require anything. Models which analysers do not return the required data will not be able to use your indicator so only list here what you really need. e.g. if you need a grade_grades record mark it as required, but there is no need to require the user object and the course as well because you can obtain them from the grade_grades item. It is very likely that the analyser will provide them as well because the principle they follow is to include as much related data as possible but do not flag related objects as required because an analyser may, for example, chose to not include the user object because it is too big and sites can have memory problems.
/**
* Allows indicators to specify data they need.
*
* e.g. A model using courses as samples will not provide users data, but an indicator like
* "user is hungry" needs user data.
*
* @return null|string[] Name of the required elements (use the database tablename)
*/
public static function required_sample_data() {
return null;
}
A single method must be implemented, calculate_sample. Most indicators make use of $starttime and $endtime to restrict the time period they consider for their calculations (for example read actions during $starttime - $endtime period) but some indicators may not need to apply any restriction (e.g. does this user have a user picture and profile description?) self::MIN_VALUE is -1 and self::MAX_VALUE is 1. We do not recommend changing these values.
/**
* Calculates the sample.
*
* Return a value from self::MIN_VALUE to self::MAX_VALUE or null if the indicator can not be calculated for this sample.
*
* @param int $sampleid
* @param string $sampleorigin
* @param integer $starttime Limit the calculation to this timestart
* @param integer $endtime Limit the calculation to this timeend
* @return float|null
*/
abstract protected function calculate_sample($sampleid, $sampleorigin, $starttime, $endtime);
Performance here is critical as it runs once for each sample and for each range in the time-splitting method; some tips:
- To avoid performance issues or repeated db queries analyser classes provide information about the samples that you can use for your calculations to save some database queries. You can retrieve information about a sample with
$user = $this->retrieve('user', $sampleid). retrieve() will return false if the requested data is not available. - You can also overwrite fill_per_analysable_caches method if necessary (keep in mind though that PHP memory is not unlimited).
- Indicator instances are reset for each analysable and time range that is processed. This helps keeping the memory usage acceptably low and prevents hard-to-trace caching bugs.
Target (core_analytics\local\target\base)
Targets must extend \core_analytics\local\target\base or its main child class \core_analytics\local\target\binary. Even if Moodle core includes \core_analytics\local\target\discrete and \core_analytics\local\target\linear Moodle 3.4 machine learning backends only support binary classifications. So unless you are using your own machine learning backend you need to extend \core_analytics\local\target\binary. Technically targets could be reused between models although it is not very recommendable and you should focus instead in having a single model with a single set of indicators that work together towards predicting accurately. The only valid use case I can think of for models in production is using different time-splitting methods for it although, again, the proper way to solve this is by using a single time-splitting method specific for your needs.
The first thing a target must define is the analyser class that it will use. The analyser class is specified in get_analyser_class.
/**
* Returns the analyser class that should be used along with this target.
*
* @return string The full class name as a string
*/
abstract public function get_analyser_class();
is_valid_analysable and is_valid_sample are used to discard elements that are not valid for your target.
/**
* Allows the target to verify that the analysable is a good candidate.
*
* This method can be used as a quick way to discard invalid analysables.
* e.g. Imagine that your analysable don't have students and you need them.
*
* @param \core_analytics\analysable $analysable
* @param bool $fortraining
* @return true|string
*/
public function is_valid_analysable(\core_analytics\analysable $analysable, $fortraining = true);
/**
* Is this sample from the $analysable valid?
*
* @param int $sampleid
* @param \core_analytics\analysable $analysable
* @param bool $fortraining
* @return bool
*/
public function is_valid_sample($sampleid, \core_analytics\analysable $analysable, $fortraining = true);
calculate_sample is the method that calculates the target value.
/**
* Calculates this target for the provided samples.
*
* In case there are no values to return or the provided sample is not applicable just return null.
*
* @param int $sampleid
* @param \core_analytics\analysable $analysable
* @param int|false $starttime Limit calculations to start time
* @param int|false $endtime Limit calculations to end time
* @return float|null
*/
protected function calculate_sample($sampleid, \core_analytics\analysable $analysable, $starttime = false, $endtime = false);
You may wish to add to the list of actions that will be offered to the recipient of an insight:
/**
* Suggested actions for a user.
*
* @param \core_analytics\prediction $prediction
* @param bool $includedetailsaction
* @param bool $isinsightuser
* @return \core_analytics\prediction_action[]
*/
public function prediction_actions(\core_analytics\prediction $prediction, $includedetailsaction = false,
$isinsightuser = false)
You may override the users who will receive insights notifications:
/**
* Returns the list of users that will receive insights notifications.
*
* Feel free to overwrite if you need to but keep in mind that moodle/analytics:listinsights
* or moodle/analytics:listowninsights capability is required to access the list of insights.
*
* @param \context $context
* @return array
*/
public function get_insights_users(\context $context)
You can implement a always_update_analysis_time() method so analysable elements' timeanalysed is only updated when analysable elements have been successfully evaluated. It is useful for lightweight targets.
/**
* Update the last analysis time on analysable processed or always.
*
* If you overwrite this method to return false the last analysis time
* will only be recorded in DB when the element successfully analysed. You can
* safely return false for lightweight targets.
*
* @return bool
*/
public function always_update_analysis_time()
If you choose to implement ignored_predicted_classes, it must be public:
/**
* Returns the predicted classes that will be ignored.
*
* @return array
*/
public function ignored_predicted_classes()
You can override the default message provided in the insight with get_insight_subject():
/**
* The insight notification subject.
*
* This is just a default message, you should overwrite it for a custom insight message.
*
* @param int $modelid
* @param \context $context
* @return string
*/
public function get_insight_subject(int $modelid, \context $context)
You can also override the URL to the insight with get_insight_context_url():
/**
* URL to the insight.
*
* @param int $modelid
* @param \context $context
* @return \moodle_url
*/
public function get_insight_context_url($modelid, $context)
Analysis interval (core_analytics\local\time_splitting\base)
Analysis intervals are used to define when the analytics API will train the predictions processor and when it will generate predictions. As explained above in the Analysis intervals documentation, they define time ranges based on analysable elements start and end timestamps.
The base class is \core_analytics\local\time_splitting\base; if what you are after is to split the analysable duration in equal parts or in cumulative parts you can extend \core_analytics\local\time_splitting\equal_parts or \core_analytics\local\time_splitting\accumulative_parts instead.
define_ranges is the main method to implement and its values mostly depend on the current analysable element (available in $this->analysable). An array of time ranges should be returned, each of these ranges should contain 3 attributes: A start time ('start') and an end time ('end') that will be passed to indicators so they can limit the amount of activity logs they read; the 3rd attribute is 'time', which value will determine when the range will be executed.
/**
* Define the time splitting methods ranges.
*
* 'time' value defines when predictions are executed, their values will be compared with
* the current time in ready_to_predict
*
* @return array('start' => time(), 'end' => time(), 'time' => time())
*/
protected function define_ranges();
A name and description should also be specified:
/**
* Returns a lang_string object representing the name for the time splitting method.
*
* Used as column identificator.
*
* If there is a corresponding '_help' string this will be shown as well.
*
* @return \lang_string
*/
public static function get_name() : \lang_string;
Analysis intervals can now override the following:
valid_for_evaluation().
You can return false if the time-splitting method can not be used to evaluate prediction models or if it does not make sense to evaluate prediction models with it, as for example upcoming_periodic children classes.
include_range_info_in_training_data() and get_training_ranges().
They can be used to create time splitting methods with a pre-defined number of ranges.
The following cannot be overwritten:
\core_analytics\local\time_splitting\base::append_rangeindex and \core_analytics\local\time_splitting\base::infer_sample_info \core_analytics\local\analyser\base::get_most_recent_prediction_range have been moved to \core_analytics\local\time_splitting\base::get_most_recent_prediction_range and it is not overridable by time splitting methods.
Calculable (core_analytics\calculable)
Leaving this interface for the end because it is already implemented by \core_analytics\local\indicator\base and \core_analytics\local\target\base but you can still code targets or indicators from the \core_analytics\calculable base if you need more control.
Both indicators and targets must implement this interface. It defines the data element to be used in calculations, whether as independent (indicator) or dependent (target) variables.
How to create a model
New models can be created and implemented in php, and can be packaged as a part of a Moodle plugin for distribution. An example of model components and models are provided at https://github.com/dmonllao/moodle-local_testanalytics.
Third party plugin developers can add their new elements (for example targets, indicators, and so on) to the documentation pages provided for those components. These documentation pages are linked from the web UI for editing models.
Define the problem
Start by defining what you want to predict (the target) and the subjects of these predictions (the samples). You can find the descriptions of these concepts above. The API can be used for all kinds of models, though if you want to predict something like "student success," this definition should probably have some basis in pedagogy. For example, the included model Students at risk of dropping out is based on the Community of Inquiry theoretical framework, and attempts to predict that students will complete a course based on indicators designed to represent the three components of the CoI framework (teaching presence, social presence, and cognitive presence). Start by being clear about how the target will be defined. It must be trained using known examples. This means that if, for example, you want to predict the final grade of a course per student, the courses being used to train the model must include accurate final grades.
How many predictions for each sample?
The next decision should be how many predictions you want to get for each sample (e.g. just one prediction before the course starts or a prediction every week). A single prediction for each sample is simpler than multiple predictions at different points in time in terms of how deep into the API you will need to go to code it.
These are not absolute statements, but in general:
- If you want a single prediction for each sample at a specific point in time you can reuse a site-wide analyser or define your own and control samples validity through your target's is_valid_sample() method.
- If you want multiple predictions at different points in time for each sample reuse an analysable element or define your own (extending
\core_analytics\analysable) and reuse or define your own analyser to retrieve these analysable elements. You can control analysers validity through your target's is_valid_analysable() method. - If you want predictions at activity level use a "by_course" analyser as otherwise you may have scalability problems (imagine storing in memory calculations for each grade_grades record in your site, though processing elements by courses help as we clean memory after each course is processed)
This decision is important because:
- Analysis intervals are applied to analysable time start and time end (e.g. Quarters can split the duration of a course in 4 parts).
- Prediction results are grouped by analysable in the admin interface to list predictions.
- By default, insights are notified to users with
moodle/analytics:listinsightscapability at analysable level (though this is only a default behaviour you can overwrite in your target).
Several of the existing analysis intervals are proportional to the length of the course (for example quarters, tenths, and so on). This allows courses with different lengths to be included in the same sample, but requires courses to have defined start and end dates.
Other analysis intervals such as "Upcoming 3 days" are also available, which do not depend on the defined length of the course. These would be more appropriate for self-paced courses without fixed start and end dates.
You do not need to require a single analysis interval at this stage, and they can be changed whenever the model is trained. You do need to define whether the model will make a single prediction or multiple predictions per analysable.
Create the target
As specified in the Target section.
Create the model
To add a new model to the system, it must be defined in a PHP file. Plugins and core subsystems declare default prediction models by describing them in their db/analytics.php file. Models should not be created manually via the db/install.php file any more. (It is also possible to execute the necessary commands in a standalone PHP file that references the Moodle config.php.)
To create the model, specify at least its target and, optionally, a set of indicators and a time splitting method:
// Instantiate the target: classify users as spammers
$target = \core_analytics\manager::get_target('\mod_yours\analytics\target\spammer_users');
// Instantiate indicators: two different indicators that predict that the user is a spammer
$indicator1 = \core_analytics\manager::get_indicator(
'\mod_yours\analytics\indicator\posts_straight_after_new_account_created'
);
$indicator2 = \core_analytics\manager::get_indicator(
'\mod_yours\analytics\indicator\posts_contain_important_viagra'
);
$indicators = [
$indicator1->get_id() => $indicator1,
$indicator2->get_id() => $indicator2,
];
// Create the model.
// Note that the 3rd and 4rd arguments (the time splitting method and the predictions processor)
// are optional.
// The 4th argument is available from Moodle 3.6 onwards.
$model = \core_analytics\model::create(
$target,
$indicators,
'\core\analytics\time_splitting\single_range',
'\mlbackend_python\processor'
);
Models are disabled by default because you may be interested in evaluating how good the model is at predicting before enabling them. You can enable models using Moodle UI or the analytics API:
$model->enable();
Indicators
You already know the analyser your target needs (the analyser is what provides samples) and, more or less, what time splitting method may be better for you. You can now select a list of indicators that you think will lead to accurate predictions. You may need to create your own indicators specific to the target you want to predict.
You can use "'Site administration > Analytics > Analytics models"' to see the list of available indicators and add some of them to your model.
API usage examples
This is a list of prediction models and how they could be coded using the Analytics API:
Students at risk of dropping out (based on student's activity, included in Moodle 3.4)
- Time splitting: quarters, quarters accumulative, deciles, deciles accumulative...
- Analyser samples: student enrolments (analysable elements are courses)
target::is_valid_analysable- For prediction = ongoing courses
- For training = finished courses with activity
target::is_valid_sample= true- Based on assumptions (static): no, predictions should be based on finished courses data
Not engaging course contents (based on the course contents)
- Time splitting: single range
- Analyser samples: courses (the analysable elements is the site)
target::is_valid_analysable= truetarget::is_valid_sample- For prediction = the course is close to the start date
- For training = no training
- Based on assumptions (static): yes, a simple look at the course activities should be enough (e.g. are the course activities engaging?)
No teaching (courses close to the start date without a teacher assigned, included in Moodle 3.4)
- Time splitting: single range
- Analyser samples: courses (the analysable elements is the site) it would also work using course as analysable
target::is_valid_analysable= truetarget::is_valid_sample- For prediction = course close to the start date
- For training = no training
- Based on assumptions (static): yes, just check if there are teachers
Late assignment submissions (based on student's activity)
- Time splitting: close to the analysable end date (1 week before, X days before...)
- Analyser samples: assignment submissions (analysable elements are activities)
target::is_valid_analysable- For prediction = the assignment is open for submissions
- For training = past assignment due date
target::is_valid_sample= true- Based on assumptions (static): no, predictions should be based on previous students activity
Spam users (based on suspicious activity)
- Time splitting: 2 parts, one after 4h since user creation and another one after 2 days (just an example)
- Analyser samples: users (analysable elements are users)
target::is_valid_analysable= truetarget::is_valid_sample- For prediction = 4h or 2 days passed since the user was created
- For training = 2 days passed since the user was created (spammer flag somewhere recorded to calculate target = 1, otherwise no spammer)
- Based on assumptions (static): no, predictions should be based on users activity logs, although this could also be done as a static model
Students having a bad time
- Time splitting: quarters accumulative or deciles accumulative
- Analyser samples: student enrolments (analysable elements are courses)
target::is_valid_analysable- For prediction = ongoing and course activity
- For training = finished courses
target::is_valid_sample= true- Based on assumptions (static): no, ideally it should be based on previous cases
Course not engaging for students (checking student's activity)
- Time splitting: quarters, quarters accumulative, deciles...
- Analyser samples: course (analysable elements are courses)
target::is_valid_analysable= truetarget::is_valid_sample- For prediction = ongoing course
- For training = finished courses
- Based on assumptions (static): no, it should be based on activity logs
Student will fail a quiz (based on things like other students quiz attempts, the student in other activities, number of attempts to pass the quiz...)
- Time splitting: single range
- Analyser samples: student grade on an activity, aka grade_grades id (analysable elements are courses)
target::is_valid_analysable- For prediction = ongoing course with quizzes
- For training = ongoing course with quizzes
target::is_valid_sample- For prediction = more than the X% of the course students attempted the quiz and the sample (a student) has not attempted it yet
- For training = the student has attempted the quiz at least X times (X because if after X attempts has not passed counts as failed) or the student passed the quiz
- Based on assumptions (static): no, it is based on previous students records
Clustered environments
The analytics/outputdir setting can be configured by Moodle sites with multiple frontend nodes to specify a directory shared across nodes. This directory can be used by machine learning backends to store trained algorithms (for example, its internal variables weights) to use them later to get predictions.
The Moodle cron lock will prevent multiple executions of the analytics tasks that train machine learning algorithms and get predictions from them.